Sei DB Deep Dive

Last updated 09/09/2025
Faster, More Efficient Storage for Sei
If you would like to be notified about future technical blog posts, product news and developer initiatives, you can sign up for the Sei blog mailing list using the form at the bottom of this article.
Setting the Scene
In July 2024, Sei V2 - the first parallelized EVM blockchain - went live. This upgrade allowed Sei to get the performance of Solana and the reliability, tooling, and mindshare of Ethereum, using optimistic parallelization to support more transactions that are processed per second.
Processing more transactions results in more blockchain state being created, so it’s insufficient to just parallelize the runtime - state management also needs to be accounted for. One of the major components of Sei v2 is SeiDB, which fundamentally changes the way that state access, state commitment, and state storage work.
SeiDB solves for state i/o with parallelized execution in mind, along with state bloat and state sync times, all while ensuring that node hardware requirements remain low.
This blog post will go over the most important parts of SeiDB.
Key Takeaways
The key takeaways are that SeiDB :
- Reduces active state size by 60%
- Reduces historical data growth rate by ~90%
- Improves state sync times by 1200% and block sync time by 2x
- Enables 287x improvement in block commit times
- Provides faster state access and state commit resulting in overall TPS improved by 2x
- All while ensuring Sei archive nodes are able to achieve the same high performance as any full node.

State Bloat: The Blockchain Storage Problem
Active State
All blockchains require nodes to store data onchain to be able to reach consensus on the state of the chain. This data usually grows over time. As a result, critical chain level operations becomes much slower when the chain state grows to above a certain level:
- Snapshot creation can take up to several hours to complete. This leads to the latest snapshot being too far from the latest block height, so nodes face a longer catch up period after they have completed a state sync
- State sync also slows down as the snapshot size gets increasingly bigger. Restoring from a snapshot goes from minutes to hours
- Block sync could take several hours to complete in order to catch up from the snapshot height to the latest chain height
- Validator nodes would see bad signing performance and an increase in block time after running for a long time
- Performing a rollback of a single block could take many hours to complete
- Dumping the state data for investigation takes a couple of hours, making debugging and disaster recovery more difficult and troublesome
Another issue that leads to large state size is write amplification (the ratio of storage space used to the amount of “useful” data actually stored). Using Sei v1 storage, this ratio was roughly 2.5x. So, to store 10GB of actual application state, 15GB of metadata is required (25GB total).
Historical State
Historical data also grows a lot. On the atlantic-2 testnet with Sei V1, archive node disk usage was growing at more than 150 GB per day - around 1TB per week!
Storage growth at this scale can lead to several negative impacts:
- As the node runs over time, performance would keep degrading, e.g., RPC nodes would start to fall behind and require constant state sync in order to keep up.
- Increasing storage capacity at this rate places a significant financial burden on service providers' infrastructure, which could become unsustainable.
- Archive nodes would not be able to keep up with the chain.
- Historical queries can be very slow.
Enter SeiDB: Faster Storage for the Fastest Blockchain
In order to live up to the reputation of being the fastest blockchain, Sei’s new storage layer must effectively deal with the state bloat issue. This would simultaneously help to speed up block time and transaction execution, which would result in increased TPS.
The Sei Labs engineering team has built on the work laid out in ADR-065 (Architecture Decision Record) by the Cosmos SDK team, to develop SeiDB.
The main approach taken was to avoid storing everything in one giant database, by decoupling the data into two different layers:
- The State Commitment (SC) - This stores the active chain state data in a memory mapped Merkle tree, providing fast transaction state access and Merkle hashing
- The State Store (SS) - Specifically designed and optimally tuned for full and archive nodes to serve historical queries
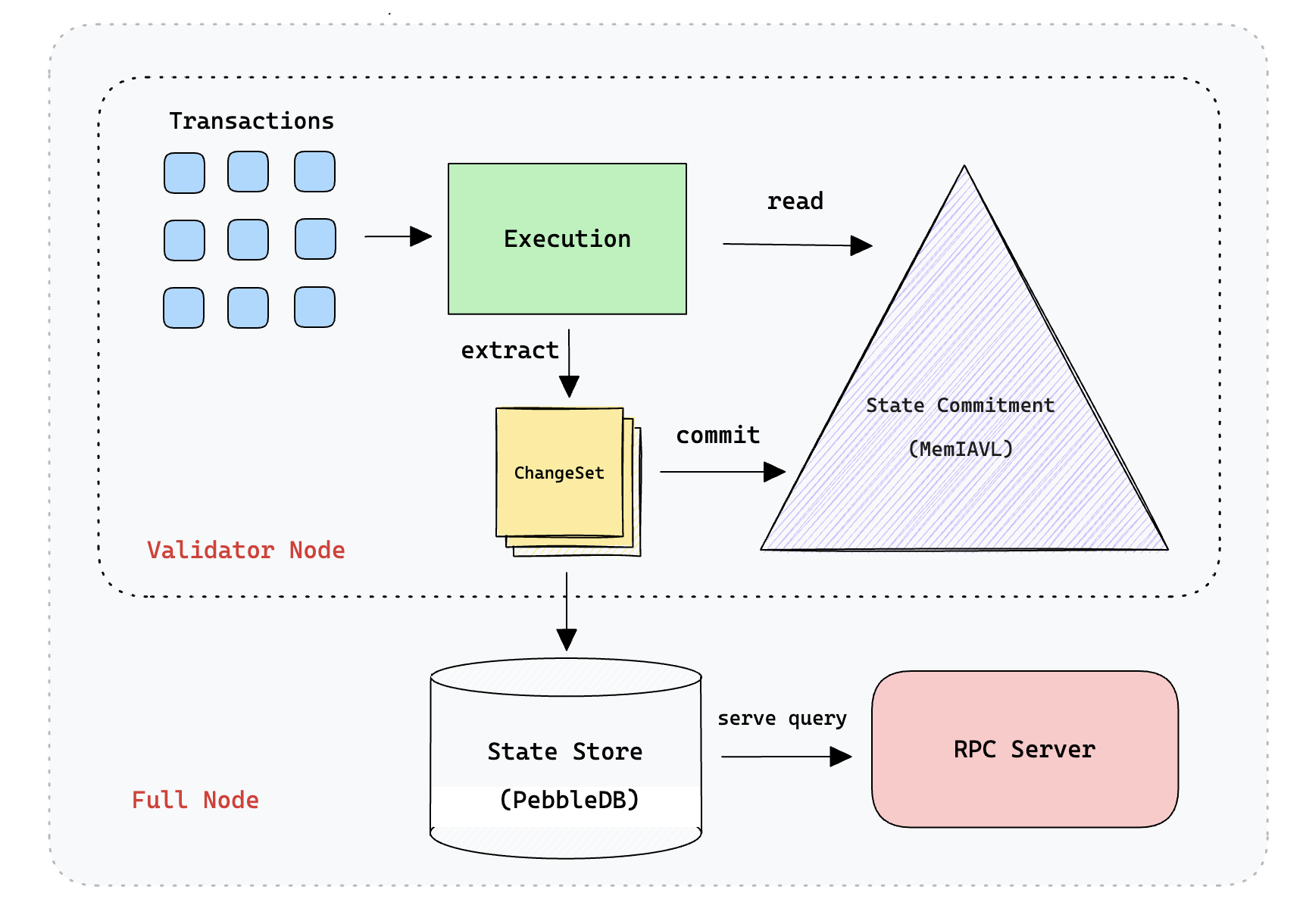
Figure 1: Schematic representation of SeiDB’s distinction of State Commitment and State Storage
State Commitment (SC) Layer
The delineation of active state and historical data massively improves performance for all node operators in the Sei ecosystem. This design enabled the Sei Lab’s engineering team to represent the current chain state as a memory-mapped IAVL tree using MemIAVL.
This in turn allows validator nodes to keep track of blockchain state using mmap that allows state access to be on the order of 100s of nanoseconds rather than 100s of microseconds, which gives huge improvements to state syncing times, and read/write amplification.
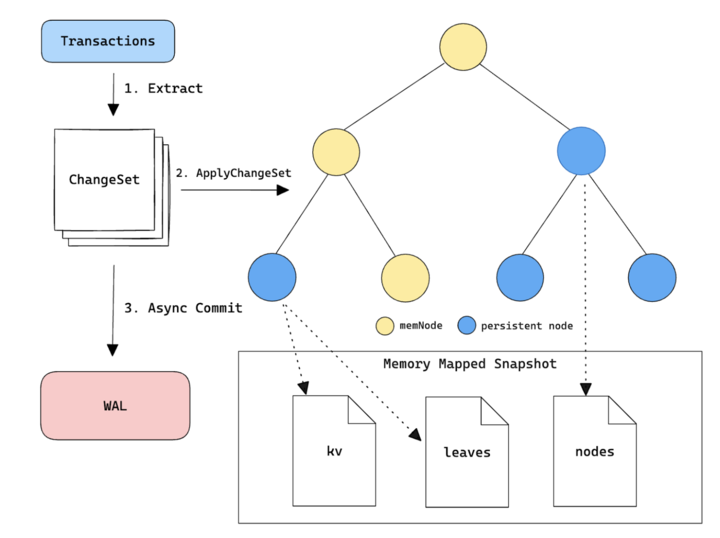
When a new block is committed, SeiDB first extracts the changesets from the transactions of that block, and applies those changes to the memory mapped IAVL tree to calculate the block hash. Then it will flush these changesets into the write ahead log (WAL) asynchronously. Validator nodes do not need to serve historical queries, and therefore only need to keep the latest few blocks. A snapshot is taken periodically of the in-memory tree and persisted on disk. The WAL will contain the changesets since the last snapshot. When a node crashes, it can then quickly recover by loading from the snapshot height and replaying the changesets in the WAL to catch up to the previous state.
Benchmarks
Benchmarking results on both the Sei test and main networks has validated this approach. On the Sei v1 Atlantic-2 testnet:
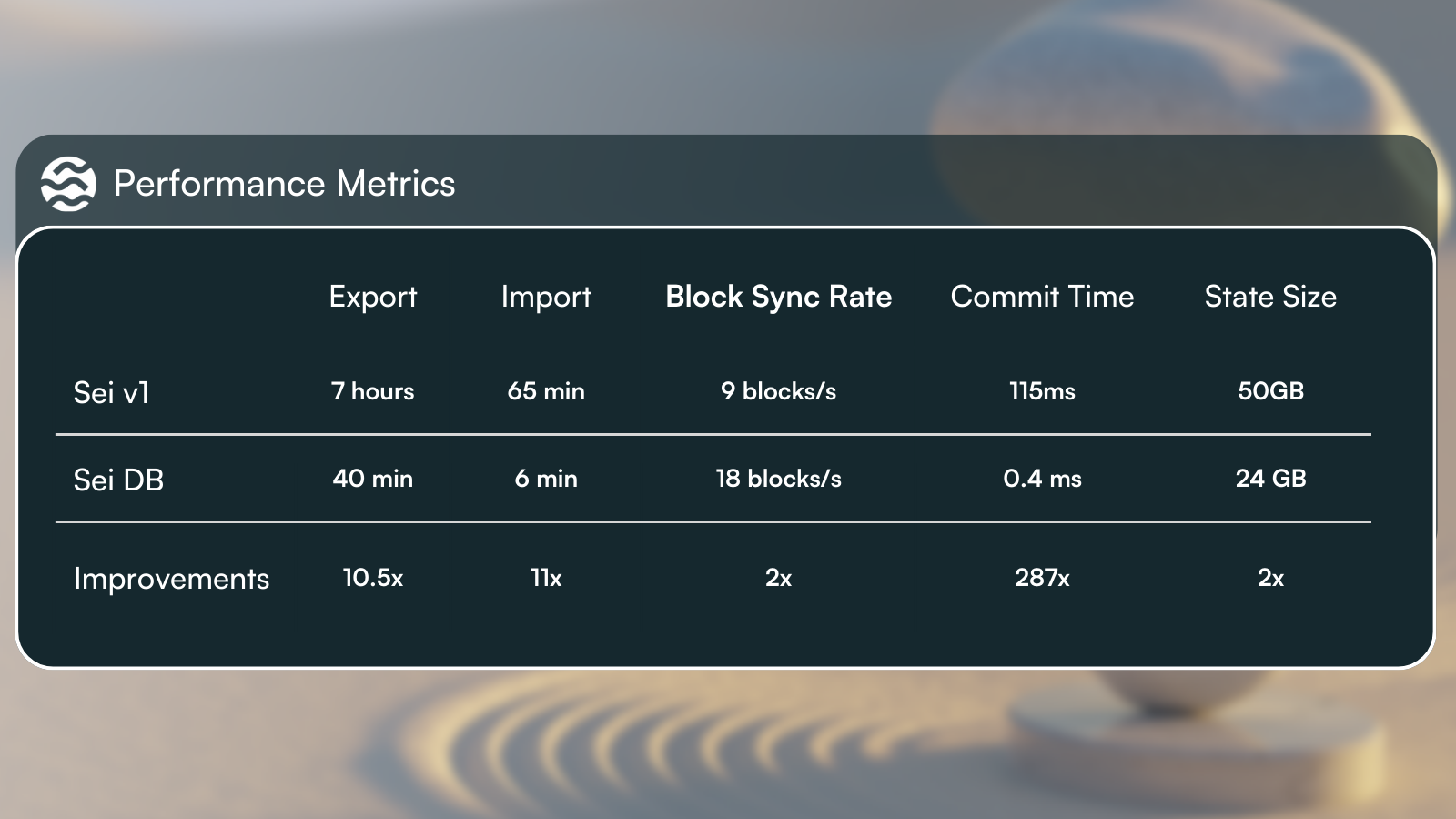
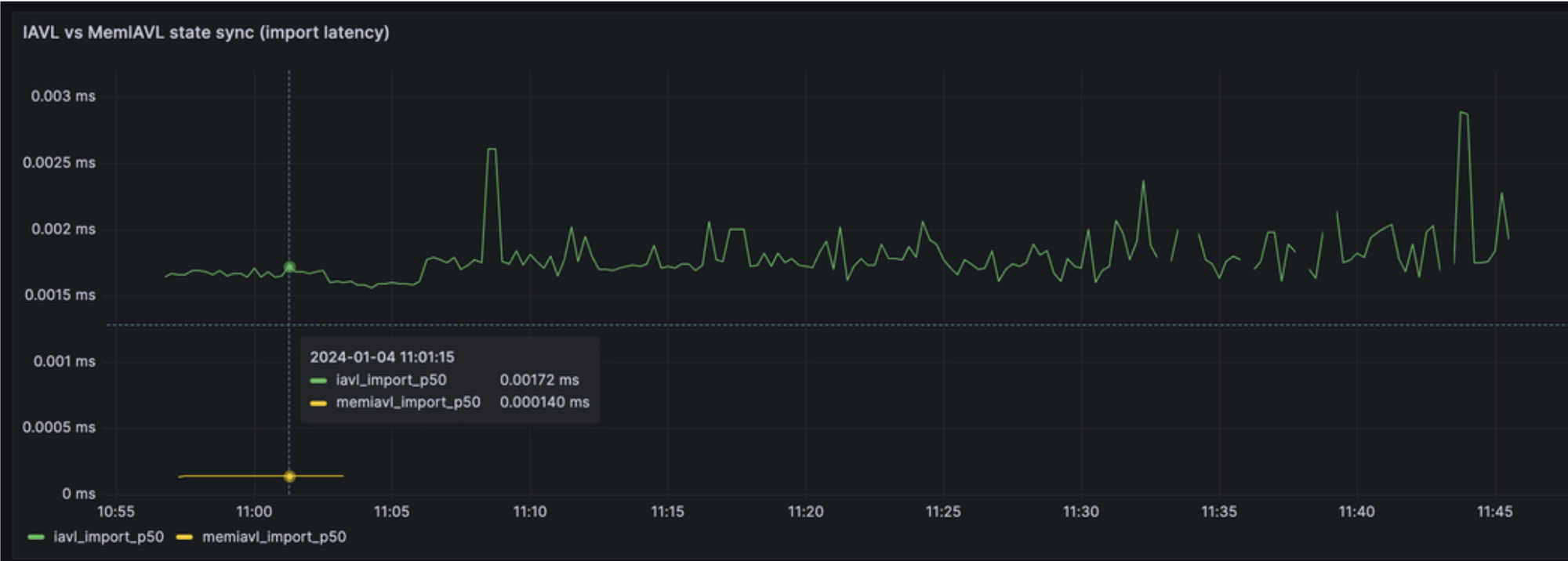
SeiDB results in 1200% speedup for state sync (that's why the yellow line is so much smaller than the green one in figure 3). This is due to less metadata requirements, and faster read & writes to access the state from MemIAVL.
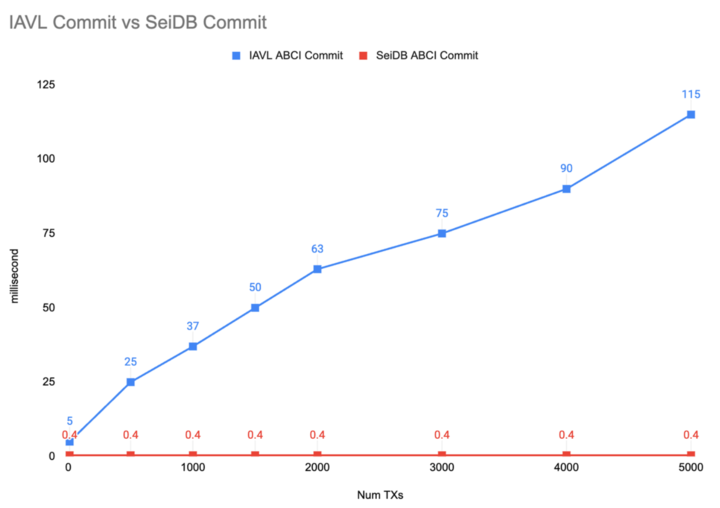
Since SeiDB commits all transaction states in an asynchronous manner, commit latency is going to look constant regardless of how many transactions we are handling in a single block. Our most recent benchmark shows that we can get up to 287x times speedup for ABCI block commit latency after switching to SeiDB.
All these performance improvement numbers are huge. This is a solid and speedy foundation which will support validator nodes on Sei networks into the future. But what about archive and RPC nodes, which need to keep historical data? SeiDB has improvements for them, too.
State Storage (SS) Layer
The state storage (SS) layer is designed to store and service historical chain data. In Sei v1, versioned IAVL trees would be stored on a LevelDB backend. This stored a lot of metadata (see write amplification referenced above) and had an inefficient schema which can be hard to interpret without sophisticated IAVL libraries.
The Sei Lab’s engineering team, has solved these issues by storing the raw key-value pairs in the SS layer, with a minimum subset of metadata. An optimized schema with a pure key-value store which doesn’t use hashes takes better advantage of locality in LSM trees. In addition, pruning has been made asynchronous so that nodes do not fall behind the chain when it is turned on.
These modifications have resulted in at least 60% reduction in state storage size requirement, due to needing less metadata. With a more optimized SS store in SeiDB, write amplifications are greatly reduced, which result in reduction of total data growth rate by 90%. Thus, the longer the node runs, the more disk saving we will be able to observe in the long term.
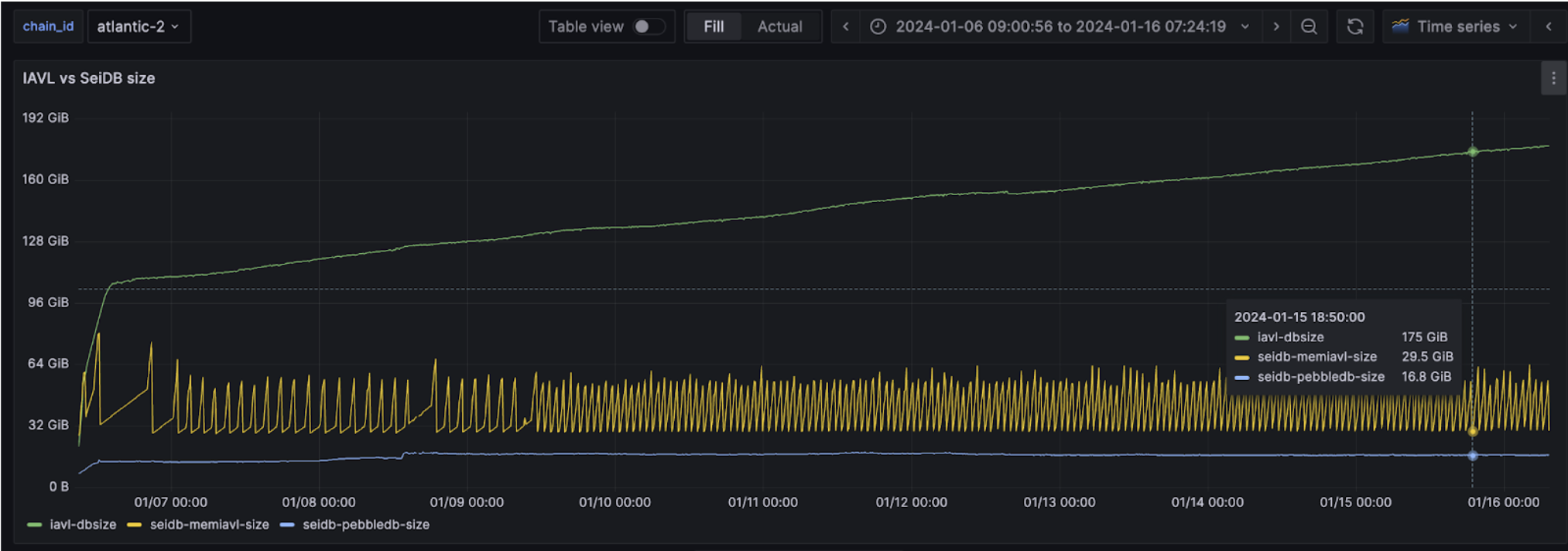
Node operators can take advantage of this reduced storage requirement, as well as significantly reduced state sync times. This results in lower infrastructure costs and greater operational efficiency.
Flexible DB Backend Support
SeiDB recognises that node operators have a variety of requirements and storage needs. The SS has therefore been built to support a variety of backends to allow operators freedom and flexibility.
Extensive benchmarking was conducted with Sei chain key-value data measuring random write, read and forward / back iteration performance for RocksDB, SQLite and PebbleDB. These experiments were conducted to inform the design of Sei V2 internally, and to serve the community as a starting point for future architectural discussions and optimizations.
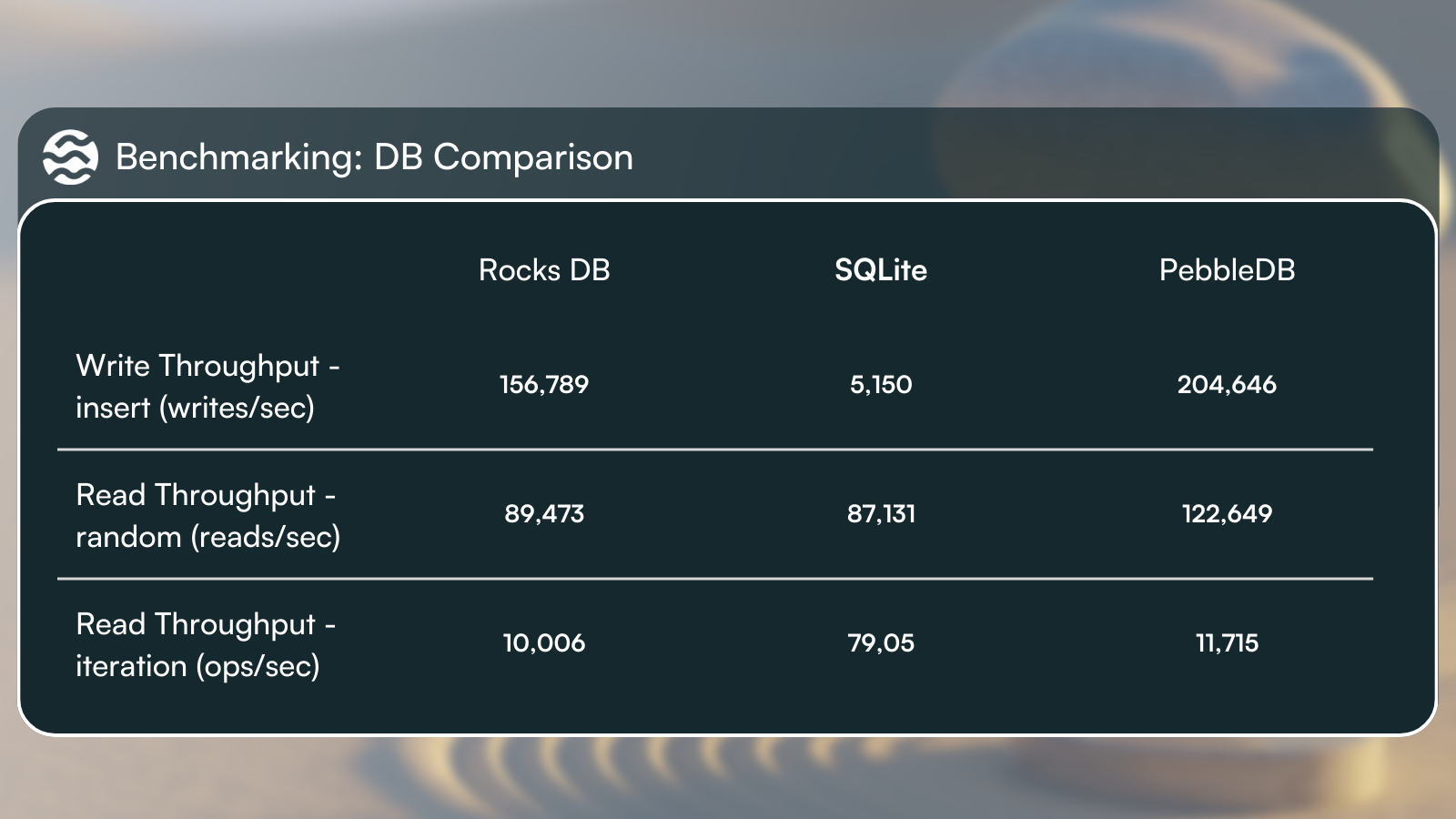
This raw database performance enables archive and RPC nodes to serve historical queries in a more scalable and storage efficient manner using Sei v2. While PebbleDB achieved the best performance in benchmarking tests, there are advantages and disadvantages to using each of these database backends:

Resources: goleveldb , CGO , cockroackdb
Conclusion
The Sei Labs engineering team has significantly optimized Sei blockchain storage and implemented a highly performant and efficient solution which has resulted in huge speedups on key benchmarks, as well as significant improvements to UX for different types of node operators.
This continuing work on SeiDB by the Sei Labs engineering teams will increase storage speed, performance and reliability and contribute to higher TPS and throughput on the Sei blockchain.
We would like to give kudos to the contributions toward this work by Bez from Cosmos SDK and the Cronos team with their proposal of MemIAVL.
If you would like to be notified about future technical blog posts, product news and developer initiatives, you can sign up to the Sei blog mailing list.