Scaling the EVM from First Principles: Reimagining the Storage Layer

Special thanks to Philippe Dumonet, Lefteris Kokoris-Kogias, Patryk Krasnicki, dcbuilder.eth, Evan Pappas, Rishin Sharma, Anastasios Andronidis, for feedback and discussions.
Introduction
The storage layer of blockchain virtual machines is critical as it manages persistent data such as smart contracts and accounts, as well as their internal states and variables. Storage operations on the EVM are among the most resource intensive and costly in terms of gas, which is directly correlated to how efficiently the EVM handles storage operations. Storing data on Ethereum is expensive because the EVM recomputes the hashes from the leaf node all the way up to the root. As the MPT grows in size and depth, the computational complexity increases for both read and write operations.
As more smart contracts are deployed and more data is stored, the blockchain state grows continuously, leading to "state bloat." This issue increases the storage requirements for nodes, particularly full nodes, which must store the entire state to validate transactions, making it increasingly more resource-intensive to participate in the network with consumer-grade hardware.
The inefficiencies in read/write operations caused by state bloat limit developers' design space and increase costs for consumers. In this article we explore ways to mitigate those limitations.
The EVM Storage Layer and its Limitations
The EVM storage layer is responsible for maintaining persistent, yet mutable data that persists even after a smart contract has finished executing. This is different from the EVM's memory, which is used for short-term, temporary data during contract execution.
EVM's persistent storage components:
- Program Code: The compiled bytecode of smart contracts, stored on the blockchain and immutable once deployed.
- Program Storage: State variables within smart contracts that hold data across executions.
- Machine State: Account-related information such as balances and nonces, which are updated with each transaction, block data, transaction receipts and logs.
The EVM uses a modified version of the Patricia Merkle Tree. Tries are tree-like data structures that allow for efficient storage and retrieval of key-value pairs.
Ethereum has:
- State Trie: Contains the state of all accounts, mapping addresses to account states.
- Storage Trie: For each account that is a smart contract, there's a storage trie holding the contract's data.
- Transaction Trie: Stores all transactions included in a block.
- Receipt Trie: Holds receipts of all transactions, including logs and status information.
Only the root hashes of these tries are stored in the block headers, ensuring data integrity while preventing block headers from becoming too large.
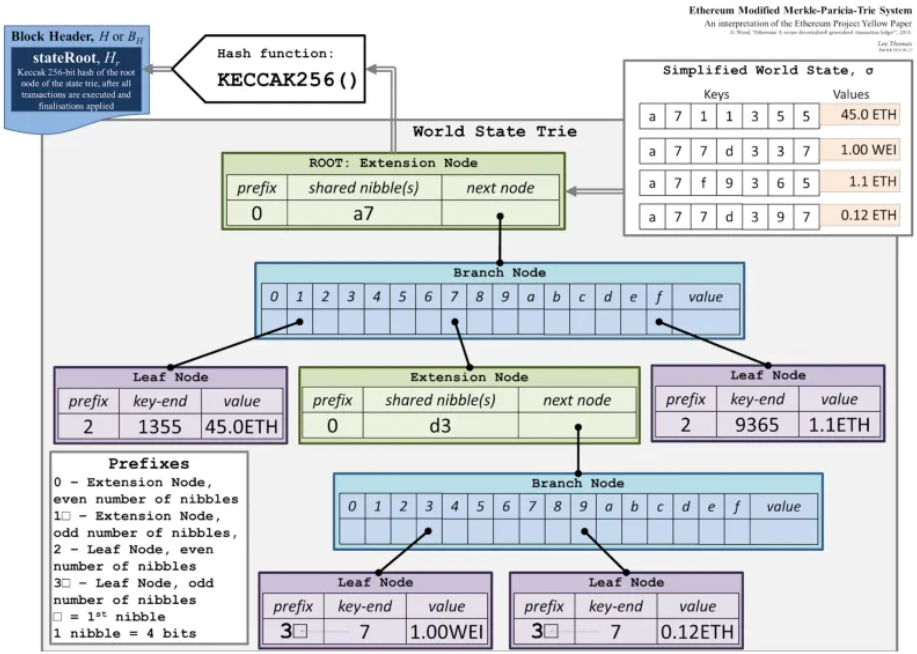
Ethereum maintains a multi-client approach, and it intentionally has no reference client that everyone must run to increase redundancy, security, technical and political decentralization, and promote experimentation for improvements. The goal is to ensure that no consensus or execution client makes up more than ⅔ of the network.
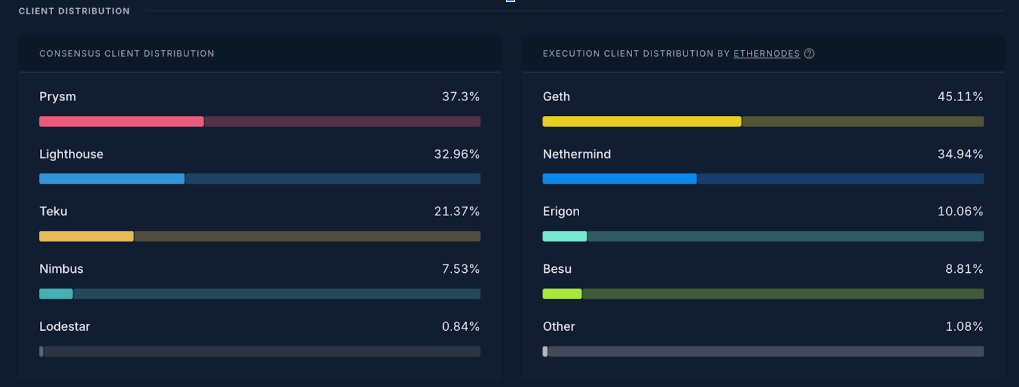
Each client variant follows the specs but takes different implementation approaches resulting in different performance metrics.
Geth
The first Ethereum client is written in Go, and it uses LevelDB, a key-value storage library optimized for fast reads and writes. It implements the Merke Particia Trie as it was specified in the Yellow Paper and uses snapshots to optimize state access and improve sync times.
Besu
It is written in Java, and it uses RocksDB, an embeddable persistent key-value store for fast storage, which is a fork of LevelDB optimized for SSDs. It implements the Merkle Patricia Trie and has advanced caching mechanisms to enhance performance.
Nethermind
Written in C# using the .NET Core framework, it uses LMDB (Lightning Memory-Mapped Database) for efficient data storage, and optimizations such as memory cache for frequently accessed nodes and write cache to batch database operations.
Erigon
It’s written in Go and it uses a custom storage layer built on MDBX (Memory-Mapped Database eXtreme). It largely eliminates the runtime MPT structure, while maintaining MPT compatibility by computing state roots when needed. Instead, the state trie is flattened into a key-value DB to reduce complexity. This eliminates the need for multiple database lookups that MPT requires, it provides better storage efficiency, reduced disk space requirements, and reduces disk I/O compared to MPT-based clients.
Silkworm, also known as Erigon++, is a C++ implementation of the Ethereum protocol based on Erigon’s architecture. It also uses libmdbx as a DB engine and it seeks to further optimize client performance and resource utilization. Currently under development, not in alpha yet.
Reth
Reth takes a modular, library-first approach to Ethereum client development. Written in Rust for performance, it adopts Erigon's staged-sync architecture while emphasizing component reusability. Reth is implementing parallel block processing, employs table partitioning for better data organization, and implements efficient pruning strategies.
Limitations of the EVM Storage Layer
Despite the variety of clients, some core limitations persist.
High Gas Costs for Storage Operations
- Expensive Writes: Writing data to storage is one of the most costly operations in Ethereum, consuming substantial gas. For instance, setting a non-zero storage slot costs 20,000 gas. As the trie grows, the time it takes to update storage increases. Nodes require more CPU resources to process storage writes, as they must recompute hashes for larger trie sections.
- Expensive Reads: Reading from storage is less expensive than writing but still incurs significant gas fees compared to operations that use memory.
State Bloat
- Growing State Size: As more smart contracts are deployed and more data is stored, the Ethereum state grows continuously. This "state bloat" increases the hardware storage requirements for nodes.
- Impact on Nodes: Full nodes must store the entire state to validate transactions, making it increasingly resource-intensive to participate in the network.
Merkle Patricia Trie Complexity & Inefficient Data Retrieval
- Structure Deepening: While Patricia Tries optimize for data integrity and verification, they can be less efficient for data retrieval and storage updates. As the number of state entries increases, the trie becomes deeper and more branches are added.
- Traversal Overhead: Read/write operations require traversing multiple nodes in the trie, increasing latency.
We could charge for storage rent but that would not solve the limitations. Developers and users would be incentivized to be more careful with handling their storage requirements but this historically hasn’t worked, i.e. C vs garbage collection. Storage rent is an economic solution not a technical one.
More efficient solutions may involve alternative data structures, and/or an optimized database. Let’s explore the different approaches several blockchains have taken to optimize reads, writes, and merkleization.
Ethereum
Reads
Ethereum's state retrieval process begins with the stateRoot in each block's header, which is the root hash of the state trie after processing that block's transactions. To access current state data, nodes start from the latest block's stateRoot. Account information is retrieved by first hashing the account address with Keccak-256, creating a key for the state trie. The node then traverses this trie, following the path defined by the key's nibbles (half-bytes) from root to leaf, often involving database lookups for each node.
For any kind of account including Externally Owned Accounts (EOAs), the retrieved data includes balance and nonce. For contract accounts, additional fields are stored:
- codeHash: The hash of the contract's bytecode.
- storageRoot: The root hash of the contract's storage trie.
To execute a contract, the EVM must retrieve the actual bytecode. The codeHash is used to locate and verify the bytecode stored in the node's code storage (usually a separate key-value store). This involves accessing the code storage using the codeHash as the key to fetch the bytecode. To access specific contract storage variables, a similar process occurs. The storage key (typically the variable's slot index) is hashed using Keccak-256. The resulting key is used to traverse the contract's storage trie, starting from the storageRoot, to retrieve the associated value.
Optimizations For Efficient data reads
Ethereum employs various optimizations to address the challenges of state management and retrieval. At the database level, Ethereum clients utilize key-value stores like LevelDB or RocksDB, which are optimized for rapid reads and writes. These clients also implement batch operations to minimize disk accesses. Caching strategies play a crucial role, with frequently accessed nodes kept in memory to reduce disk I/O, while trie node pruning helps conserve space by removing old or unused nodes. Fast sync modes, such as snapshot syncing and warp sync, allow nodes to download recent state data or rely on block headers for historical information, significantly reducing sync times.
Protocol improvements, including EIP-1052, EIP-2929, and EIP-2930, have been introduced to optimize state access patterns and more accurate gas cost calculations. Ongoing research into stateless Ethereum explores designs where clients don't need to store the entire state, instead relying on proofs for verification. Additionally, alternative data structures like Verkle Trees are being investigated to offer smaller proof sizes and faster verification.
Writes
Write operations begin with a transaction submission by a user or a smart contract. The transaction enters the mempool, where it awaits inclusion in a block proposed by validators. Validators validate the transaction by verifying its signature, nonce, and sufficient gas to execute. This process interacts with Ethereum's storage structure, primarily the state trie for accounts and storage tries for contracts. Any value changes during transaction execution require updating the corresponding trie nodes and recalculating hashes up to the root, ensuring cryptographic data integrity.
Write Optimizations Employed by Ethereum
1. Gas Cost Adjustments
- EIP-2200 (Rebalancing Gas Costs): Adjusted gas costs for SSTORE operations to better reflect the actual computational expense and incentivize efficient storage use.
- Refund Mechanisms: Gas refunds are provided when storage slots are cleared (set to zero), encouraging users to clean up unused storage.
2. Stateless Ethereum Research
- Reducing State Dependencies: Stateless clients don't need to store the entire state, relying on witnesses provided with transactions.
- Verkle Trees: Exploring alternative data structures that offer smaller proof sizes and faster verification, potentially reducing the overhead of writes.
3. Database and Storage Improvements
- Batch Writes: Grouping multiple write operations reduces the number of disk accesses, improving performance.
- Asynchronous Writes: Implementing asynchronous database writes can minimize blocking during transaction processing.
- Cache Optimization: Caching frequently accessed data and write buffers to reduce disk I/O.
4. Protocol-Level Enhancements
- EIP-1559 Fee Mechanism: Adjusts how transaction fees work, potentially affecting how users prioritize write operations based on gas prices.
- EIP-2929 and EIP-2930: Increase gas costs for certain storage operations and introduce access lists to optimize state access patterns.
- EIP-4844 introduces a new transaction type called blob-carrying transactions, which carry large amounts of data (blobs) that are not accessible to the EVM but are commited to by the consensus layer. This allows for high data throughput without increasing the state size, which optimizes write operations.
Merkleization Optimizations Explored by the Ethereum Community
To address the previously mentioned MPT limitations, the Ethereum community is exploring Verkle trees,
a form of polynomial commitment Merkle tree that allows for smaller proof sizes and more efficient verification.
Verkle proofs are significantly smaller than Merkle proofs, reducing the bandwidth required for light clients and stateless clients. Smaller proofs and more efficient verification enable better scalability and pave the way for stateless Ethereum. EIP-4844 (Proto-Danksharding) introduces data availability sampling and lays the groundwork for implementing Verkle trees. By reducing the size of cryptographic proofs (witnesses), Verkle trees enable the development of stateless clients that can validate transactions without maintaining the entire state database. This efficiency is a big part of Ethereum's scalability roadmap, facilitating lighter nodes and broader network participation.
Solana
Solana's Data Storage Model
1. Flat Account Model
- Unified Account Space: Solana employs a flat account model where all accounts exist in a single, global namespace. This contrasts with Ethereum's hierarchical structure using Merkle Patricia Tries.
- Separation of Code and Data: Programs (smart contracts) and accounts (data) are separate entities. Programs are stateless code, while accounts hold the state or data that programs operate on.
- Direct Access: Accounts can be accessed directly using their public keys without the need for complex data structure traversals.
2. Memory-Mapped Account Storage
- In-Memory Database (AccountsDB): Solana stores account data in an in-memory database called AccountsDB, which uses a combination of RAM and memory-mapped files.
- Memory-Mapped Files: By leveraging memory-mapped files, Solana allows the operating system to manage data paging, enabling efficient access to data that doesn't fit entirely in RAM.
- Zero-Copy Reads: Programs can read account data directly without additional copying, reducing overhead and latency.
Optimizations for Efficient Data Reads in Solana
1. Avoidance of Complex Data Structures
- No Use of Tries for State Storage: Solana avoids the use of Merkle Patricia Tries for state storage, eliminating the overhead associated with hashing and tree traversal.
- Flat Key-Value Store: Accounts are stored in a simple key-value store, allowing for O(1) access time for reads and writes.
2. Parallel Transaction Processing with Sealevel
- Sealevel Runtime: Solana introduces Sealevel, a parallel smart contract runtime that can process thousands of transactions in parallel.
- Non-Overlapping Transactions: Transactions that do not interact with the same accounts can be executed simultaneously, increasing throughput.
- Optimized Read Access: Pre-determining non-overlapping account access patterns reduces state contention.
3. Efficient Data Serialization
- Binary Serialization Formats: Solana uses efficient binary serialization formats (like Borsh) for account data, minimizing the size and processing time.
- Zero-Copy Deserialization: Programs can access serialized data without deserialization overhead, as they operate directly on the memory-mapped data.
4. Caching and Data Locality
- RAM Caching: Frequently accessed account data is kept in RAM, reducing the need for disk access and improving read speeds.
- Data Locality Optimizations: Solana optimizes data placement to improve cache hits and reduce latency.
5. Snapshot Mechanism for State Syncing
- Incremental Snapshots: Solana uses snapshots of the current state to help new validators join the network quickly without processing the entire transaction history.
- Efficient State Reconstruction: This reduces the time and data reads required to reconstruct the current state.
6. Optimistic Concurrency Control
- Conflict Detection: During transaction execution, Solana detects read-write and write-write conflicts at the account level. Developers don’t need to declare state dependencies providing a better developer experience.
7. Account Versioning and Garbage Collection
- Versioned Accounts: Accounts include versioning to handle updates efficiently and ensure consistency during reads.
- Garbage Collection: Old account data is cleaned up to free storage space and improve read performance.
Writes
Solana's write operations leverage an account-based model separating programs from data, using a flat namespace for direct access. The system employs optimistic concurrency control and the Sealevel runtime for parallel transaction processing, with write locks ensuring data consistency. Solana's Proof of History and Tower BFT consensus accelerate transaction confirmation, while memory-mapped storage enables zero-copy writes. Transaction pipelining and GPU acceleration enhance processing speed. The platform maintains data integrity through persistent storage, periodic snapshots, and efficient data compaction.
Optimizations for Write Operations in Solana
1. Parallelization
- Maximized Hardware Utilization: Parallel processing allows Solana to fully exploit multicore processors, increasing the capacity for write operations.
- Scalability: The architecture scales with hardware improvements, supporting more transactions as processor core counts increase.
2. Optimistic Concurrency Control
- Non-Blocking Execution: By assuming transactions will not conflict and handling conflicts only when they occur, Solana minimizes the overhead associated with locking mechanisms.
- Efficient Conflict Handling: Retrying conflicted transactions make it easier for developers to write code preemptively serializing all transactions. If the number of unrelated transactions is large enough then OCC can provide meaningful optimization.
3. High-Performance Runtime Environment
- Sealevel's Efficiency: Designed for concurrency, Sealevel minimizes overhead and maximizes throughput for write operations.
- Asynchronous Execution: Non-blocking I/O and asynchronous processing prevent slow operations from stalling transaction processing.
4. Direct Account Access
- No Complex Data Structures: Without the need for hierarchical data structures, write operations involve straightforward reads and writes to accounts.
- Reduced Overhead: Eliminating complex state management reduces latency and resource consumption during writes.
5. Reduced Disk I/O
- In-Memory Data Handling: Keeping active account data in memory significantly reduces disk access times during write operations.
- Efficient Persistence: When writing to disk, Solana uses batch writes and optimized storage formats to minimize I/O overhead.
6. Streamlined Consensus
- Fast Transaction Finality: Solana achieves rapid confirmation of write transactions through its efficient consensus mechanisms.
- Low Communication Overhead: Validators require less intercommunication to agree on the ledger state, expediting the write process.
7. Transaction Fee Mechanism
- Predictable and Low Fees: Solana's fee structure encourages frequent write operations by keeping costs low and predictable.
- Dynamic Fee Adjustment: The network can adjust fees based on demand, ensuring that write operations remain efficient even under high load.
Solana’s Approach to State Management & Merkleization
Solana takes a different approach to merkleization compared to Ethereum's MPT, prioritizing performance and simplicity. Rather than using a trie structure, it employs a straightforward Merkle tree only for block validation, where each block contains a state root hash computed from all account states. The system directly hashes account states using SHA-256, incorporating elements like lamports (balance), owner information, executable flags, rent epoch, and account data.
This simplified merkleization strategy aligns with Solana's flat account model and emphasis on high throughput. State validation occurs primarily during transaction execution through runtime verification rather than cryptographic proofs. By eliminating complex tree traversals and intermediate nodes, it achieves faster state access and updates while reducing storage overhead. However, this approach comes with trade-offs – validators must maintain the complete current state in memory, and proof generation is less granular than in Ethereum's MPT system. This design maximizes performance at the cost of higher memory requirements for validators.
Sui
Sui’s Data Storage Model
Sui's data storage model centers around an object-centric approach, where objects serve as the fundamental unit for both storage and computation. These objects encapsulate state and behavior, representing user data and smart contracts alike. Sui maintains a global object store, with each object uniquely identified by an Object ID within a flat namespace, enabling direct and efficient access.
The platform leverages the Move programming language, which is purposefully built for safe and verifiable smart contract development. Move's resource-oriented model aligns seamlessly with Sui's object-centric design, enhancing overall system integrity and efficiency.
Sui implements an ownership and access control system. Objects can be owned by user accounts or other objects, with ownership determining access permissions and modification capabilities. The concept of shared objects allows for concurrent access and modification by multiple transactions. This ownership model provides fine-grained access control, optimizing data reads by minimizing unnecessary contention.
Optimizations for Efficient Data Reads
1. Direct Object Access via Object IDs
- Elimination of Complex Hashing: Unlike Ethereum's use of hashed keys in tries, Sui accesses objects directly using their Object IDs.
- Flat Address Space: This simplifies data retrieval, as it reduces the need to traverse hierarchical data structures or perform extensive key-value lookups. (Sui also supports dynamic objects that might require lookups at execution time).
2. Parallel Execution of Transactions
- Single-Writer Principle for Owned Objects: Transactions involving only owned objects can be executed in parallel without conflicts, as each transaction has exclusive access to its objects.
- Multithreaded Execution: Sui's execution engine can process multiple transactions simultaneously, improving throughput and reducing read latency.
- Conflict Avoidance: By identifying non-overlapping transactions, Sui minimizes read-write conflicts, enhancing read performance.
3. Efficient Consensus Mechanism
Mysticeti: Sui optimizes for both low latency and high throughput.
- It allows multiple validators to propose blocks in parallel, utilizing the full bandwidth of the network and providing censorship resistance. These are features of the DAG-based consensus protocols.
- It takes only three rounds of messages to commit blocks from the DAGs, same as pBFT and matches the theoretical minimum.
- The commit rule allows voting and certifying leaders on blocks in parallel, further reducing the median and tail latencies.
- The commit rule also tolerates unavailable leaders without significantly increasing the commit latencies.
4. Object Versioning and Caching
- Versioned Objects: Each object carries a version number, ensuring that reads are consistent with the latest state.
- In-Memory Caching: Frequently accessed objects are cached in memory, reducing disk I/O and speeding up read operations.
- Lazy Loading: Objects are loaded into memory only when needed, optimizing resource utilization.
5. Efficient Data Serialization
- Move's Resource Model: Move enforces strict rules on resource manipulation, which aids in efficient serialization and deserialization of objects.
- Binary Serialization Formats: Objects are serialized using compact binary formats, reducing the size of data reads and the overhead of parsing.
6. Database and Storage Optimizations
- Key-Value Storage Backend: Sui uses high-performance key-value stores (e.g., RocksDB) optimized for fast reads and writes.
- Batch Reads and Writes: Transactions can batch multiple read and write operations, minimizing the number of database accesses.
- Data Pruning and Compaction: Old or unnecessary data is pruned, and storage is compacted to improve read efficiency.
7. Handling Shared Objects
- Lock-Based Concurrency Control: For transactions involving shared objects, Sui employs locks to manage access and ensure data consistency. Transactions must acquire locks on shared objects before reading or writing to them. This mechanism prevents concurrent modifications that could lead to conflicting state changes.
- Efficient Synchronization: Transactions that do not interact with the same shared objects can still execute in parallel, maximizing throughput.
Writes
Sui's write operations center on an object-centric data model, where uniquely identified objects encapsulate data and behavior. This approach enables direct access and fine-grained control through ownership. Sui leverages parallel transaction execution for independent objects, minimizing conflicts and maximizing throughput. The Move programming language ensures data integrity and efficient serialization. Sui's optimized consensus mechanism, combining swift transaction dissemination with BFT, ensures rapid and secure write confirmations. Memory-efficient data structures, including in-memory storage and effective garbage collection, further enhance write performance.
Sui’s Approach to State Management & Merkleization
Sui employs a unique approach to state management and merkleization that aligns with its object-centric architecture. Rather than using a traditional Merkle tree or MPT like Ethereum, Sui implements a directed acyclic graph (DAG) structure for organizing transactions and their effects on objects. The platform's merkleization strategy centers around object versioning and authenticated data structures that track object history and ownership.
Each object in Sui has a unique version number that increases monotonically with modifications. The system maintains merkle roots of object states at each checkpoint, using a combination of incremental verification and causal order tracking. This architecture enables parallel transaction processing while maintaining cryptographic verifiability. Instead of a global state trie, Sui uses per-object authentication paths and combines them with its Narwhal-Tusk consensus protocol for efficient state verification. This approach allows validators to process non-overlapping transactions in parallel while still maintaining strong consistency guarantees.
The key innovation in Sui's merkleization is its integration with the Move programming language's resource model. Move's ownership system ensures that objects can only be modified by their owners or designated smart contracts, which simplifies merkle proof generation and verification. By tracking object ownership and version history directly in the authenticated data structure, Sui achieves efficient state verification without the overhead of traditional merkle trees. However, this design choice means validators must maintain more detailed object history compared to systems that only track current state.
Sei
At Sei we have identified certain key challenges:
Write Amplification: The current IAVL tree structure results in high write amplification, where excessive metadata is written to disk compared to the actual useful data. This leads to inefficient storage usage and increased disk I/O.
Storage Growth: Due to write amplification and inefficient compaction, disk usage grows rapidly. This exponential growth makes running archive nodes expensive and unsustainable over time.
Slow Operations: Critical operations like state synchronization, snapshot creation, and data retrieval become increasingly slow as the blockchain state grows, impacting node performance and user experience.
DB Performance Degradation Over Time: As data size grows, LevelDB's performance significantly degrades, particularly affecting state operations. This becomes especially noticeable with larger datasets, impacting node efficiency.
Optimizations for Reads in Sei
1. Separation of State Commitment and State Storage
- State Commitment (SC): By isolating the SC layer, Sei ensures that consensus operations are fast and lightweight. The SC layer doesn't need to handle historical queries, allowing it to be optimized for speed and efficiency.
- State Storage (SS): The SS layer focuses on storing data in a way that is optimized for read-heavy workloads, particularly for serving historical queries.
2. Adoption of MemIAVL for State Commitment
Sei utilizes MemIAVL, an in-memory version of the IAVL tree, for state commitment:
- In-Memory Operations: All recent states are served from memory, significantly improving read and write speeds for consensus-related data.
- Write-Ahead Log (WAL) and Tree Snapshots: To ensure data persistence and quick recovery, MemIAVL uses a WAL to record changes and periodic snapshots of the in-memory tree. This approach minimizes disk I/O during normal operations.
Benefits for Reads:
- Faster Access: In-memory data structures provide near-instantaneous read access for consensus operations.
- Reduced Latency: Critical read operations for block validation and commitment are expedited, enhancing overall network performance.
3. Optimized State Storage for Historical Queries
For the SS layer, we propose a pluggable interface that allows integration with databases optimized for read performance:
- Scalable Storage Solutions: By choosing databases designed for high read throughput and efficient data retrieval, we ensure that historical queries are served promptly.
- Customized Database Options: Applications can select the most suitable database backend for their specific access patterns and performance requirements.
Potential Read Optimizations:
- Caching Strategies: Frequently accessed data can be cached in memory, reducing the need to read from disk.
- Batch Processing: Reading data in batches improves throughput and reduces overhead.
4. Node-Specific Configurations
Different nodes have different requirements:
- Validator Nodes:
- Memory-Centric Operations: Validators can keep all necessary data in memory, optimizing read speeds for consensus without the overhead of disk-based storage.
- Minimal Disk Usage: By focusing on the latest state and not storing historical data, validators reduce storage needs and improve performance.
- RPC and Archive Nodes:
- Persistent Storage: Nodes that serve historical data use the optimized SS layer to handle read-heavy workloads efficiently.
- High Read Performance: These nodes are configured to provide fast responses to historical queries, essential for applications and users relying on past blockchain data.
5. Improved Data Structures and Storage Techniques
By moving away from the traditional IAVL tree for state storage, Sei can employ data structures better suited for read optimization:
- Simplified Key-Value Stores: Using databases that store data in a flat key-value format reduces complexity and speeds up read operations.
- Reduced Metadata Overhead: Optimized data structures minimize the amount of metadata, decreasing storage requirements and read amplification.
Conclusion
The EVM's storage layer faces a critical challenge: storage operations require expensive hash recomputations through the MPT, making them costly and resource-intensive. As smart contracts proliferate, growing state size increases computational complexity and storage requirements, making network participation increasingly difficult with consumer hardware. These inefficiencies limit developer options and raise user costs.
The key to optimizing blockchain storage lies in recognizing that state commitment (for consensus and verification) and state storage (for data persistence) have distinct requirements and can be optimized independently. While different blockchains are exploring various approaches to this separation, Sei's implementation with MemIAVL and pluggable storage showcases how this architectural split can enable parallel execution and manage state bloat while keeping hardware requirements low. This separation allows optimization of consensus operations independently from data storage and retrieval, reducing the impact of state bloat while supporting increased transaction throughput.
Research continues to examine state management from first principles, exploring new data structures and storage approaches that can further optimize both layers while maintaining security and decentralization.
Join the Sei Research Initiative
We invite developers, researchers, and community members to join us in this mission. This is an open invitation for open source collaboration to build a more scalable blockchain infrastructure. Check out Sei Protocol’s documentation, and explore Sei Foundation grant opportunities (Sei Creator Fund, Japan Ecosystem Fund). Get in touch - collaborate[at]seiresearch[dot]io